测试基准
WRF 基准是美国大陆 (CONUS) 2.5km (https://www2.mmm.ucar.edu/WG2bench/conus_2.5_v3/) 和 12km (http://www2.mmm.ucar.edu/WG2bench/conus12km_data_v3):CONUS 2.5km 和 CONUS 12km。CONUS 12km 是 2001 年 10 月 24 日时间步长为 72 秒的 48 小时模拟。基准周期是从 24 小时结束时的重启文件开始的 25-27 小时。CONUS 2.5km 是 9 小时2005 年 6 月 4 日时间步长为 15 秒的模拟。基准周期为 6-9 小时,从第 6 小时结束时的重启文件开始。由于 CONUS 2.5km 的分辨率比 CONUS 12km 高得多,计算量更大,所以更适合测试处理器的性能和可扩展性。
测试结果
AWS Graviton2 (https://aws.amazon.com/ec2/graviton/)处理器由 AWS 使用 64 位 Arm Neoverse 内核定制构建,可为在 Amazon EC2 中运行的云工作负载提供卓越的性价比。这些实例由 64 个物理核心 AWS Graviton2 处理器提供支持,这些处理器使用 64 位 Arm Neoverse N1 核心和 AWS 设计的定制芯片,使用先进的 7 纳米制造技术构建。
由于 NWP 模型通常受益于高速网络,我们将评估 C6gn.16xlarge(基于 64 核 Graviton2 的实例)和 C5n.18xlarge(基于 Intel Skylake 的 36 核实例)。这两个实例都具有 100 Gbps 网络带宽并支持Elastic Fabric Adapter (https://aws.amazon.com/hpc/efa/) (EFA)。为了确定通过 C6gn 增加的网络功能实现的性能,我们还评估了 C6g。C6g 实例除了增加了网络功能外,还具有与 C6gn 实例相同的特性。
单实例性能
在着手解决网络的影响之前,我们在单个实例中运行 CONUS 2.5 km数据集。对于每种实例类型,我们评估了具有不同编译器版本以及 MPI 等级和 OpenMP 线程比率的多种组合。在具有 64 个物理内核的基于 Graviton2 的实例上,MPI 任务数乘以 OpenMP 线程数始终等于 64。同样,在 C5n.18xlarge 上,它有 36 个物理内核(两个插槽,每个插槽有 18 个物理内核) ),它将始终达到 36 个内核。此处使用的性能指标是模拟速度,即每个挂钟时间完成的模拟持续时间。图 1 显示了该评估的结果。 [Image: image.png] * C6gn:我们看到 GCC 10.2 和 ARM 20.3 编译器在单个实例上的性能相似(在所有情况下都在 3% 以内)。在单个节点上,每个节点也使用 16 或 32 个 MPI 等级略有优势。 * C5n:在这种情况下,英特尔编译器套件和 GCC 10.2 之间的性能差异更大,英特尔编译器在这些场景中的执行速度提高了 15-20%。
跨实例比较,c5n.18xlarge 在单个实例上比 c6gn 具有性能优势,在本测试用例中约为 5%。 测试结果表明在使用编译器标志的标准优化默认值的结果。此外,根据应用程序、规模、处理器生成和所使用的特定标志的多种因素,这些结果将发生显着变化。 对于测试的其余部分,我们将在每种情况下使用性能最高的编译器。这意味着 GCC 10.2 用于所有 Graviton2(C6g 和 C6gn)测量,英特尔编译器用于 C5n 实例测量。
多实例性能
为了更好地理解 c6gn 实例增强网络的差异,我们评估了扩展到 112 个实例的相同基准测试。C6gn.16xlarge 和 C5n.18xlarge 都包含 EFA 功能和每个实例 100 Gbps,以实现高度可扩展的节点间通信。C6g 实例使用使用弹性网络适配器 (ENA) 和 TCP/IP 的 25 Gbps 连接。作业中使用的所有实例都是作为计算置放群组的一部分启动的,这可以最大限度地提高群组实例之间的网络性能。在所有情况下,我们都使用 Open MPI 4.1.0。图 2 显示了三个实例中每一个的评估结果。我们以两种格式显示相同的结果,一种基于实例数(左),另一种基于内核数(右)。
\
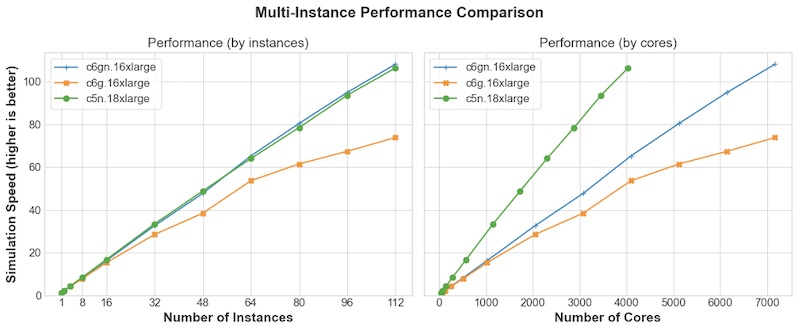
在实例级别进行比较时,C6g.16xlarge 实例的性能与其他两个实例相似,直到 16 个实例,由于网络通信增加,扩展效率进一步下降。在 112 个实例中,C5n 和 C6gn 的性能比 C6g 高约 30%,显示了 EFA 的价值和增加的网络容量。 内核数量图(右侧)的性能在外观上有所不同,因为 C5n.18xlarge 有 36 个物理内核,而基于 Graviton2 的实例(C6g、C6gn)有 64 个物理内核。在给定的核心数量下,与 C6g.16xlarge/C6gn.16xlarge 实例(每个实例 64 个核心)相比,它运行的 C5n.18xlarge 实例(每个实例 36 个核心)更多。从图表中,我们观察到 C5n.18xlarge 以每核为基础在 4,600 个核上具有近 70% 的优势,但是,在许多实例的基础上,性能几乎相同。对于本测试案例中评估的 112 个实例,它们还显示出近乎线性的扩展行为。 从测试结果来看,C6gn 和 C5n 的多实例性能的网络性能非常接近。另外网络测试的结果和在单个实例网络测试的结果很相似。
性价比
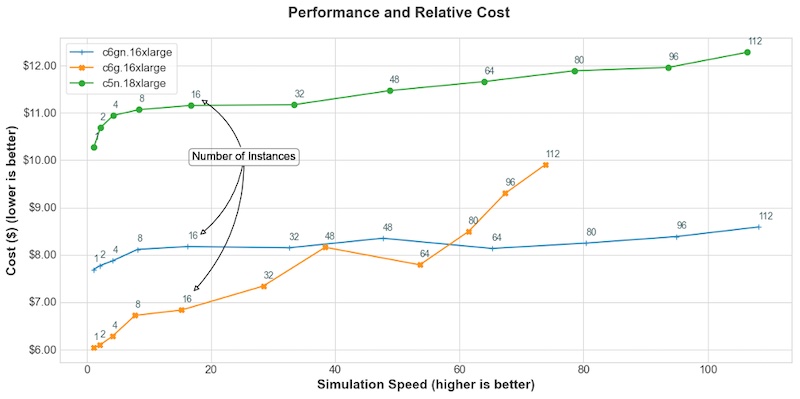
使用美国东部(弗吉尼亚北部)地区的最新定价,绘制了核心仿真成本与针对该成本获得的仿真速度(与实时相比的加速)的关系图。这仅包括花费在应用程序计算部分的时间,但不包括 I/O 时间,I/O 时间可能因所需输出属性、I/O 库和所用文件系统的选择而异。 [Image: image.png] C6gn 在较低的模拟速度下提供了显着的节省(与模拟速度接近 16 核的 C5n.18xlarge 相比节省了约 40%),并且当需要更快的模拟速度时,C6gn.16xlarge 成本最低(与 C5n.18xlarge 相比,模拟速度为 100 时节省 30%)。 在较低的模拟速度(和较少的实例数)下,因为模拟没有利用 C6gn.16xlarge 提供的高速网络,所以成本较低的 C6g.16xlarge 性价比最高。但在更大的范围内,由于每个实例需要处理的网格点较少,并且网络对性能更重要。因此 C6gn 实例具有更高的性价比。
总结
使用 WRF 在由基于 Arm 的 AWS Graviton2 处理器提供支持的 Amazon EC2 C6g/C6gn 实例上运行单节点和大规模多节点 NWP 模拟的性能。与基于 Intel 的 C5n 实例相比,在基于 Arm 的 AWS Graviton2 (C6g/C6gn) 实例上运行这些 NWP 模拟具有高达 40% 的性价比优势。由于 EFA 提供的高速网络,甚至 C6gn 上的周转时间(以模拟速度衡量)也与 C5n 实例几乎相同。
根据上述测试结果来选择WRF on AWS 的技术架构决策。